



タンパク質の機能予測を省力化



分子シミュレーションとタンパク質言語モデルを組み合わせて教師データを拡張
ポイント
・ 機械学習を用いたタンパク質の機能値予測において、分子シミュレーションとタンパク質言語モデルで計算された機能値を疑似的な教師データとして活用
・ 少数の実験データしか得られない状況でも精度の高いタンパク質の機能値予測を実現
・ 機能性タンパク質の効率的な開発が可能に
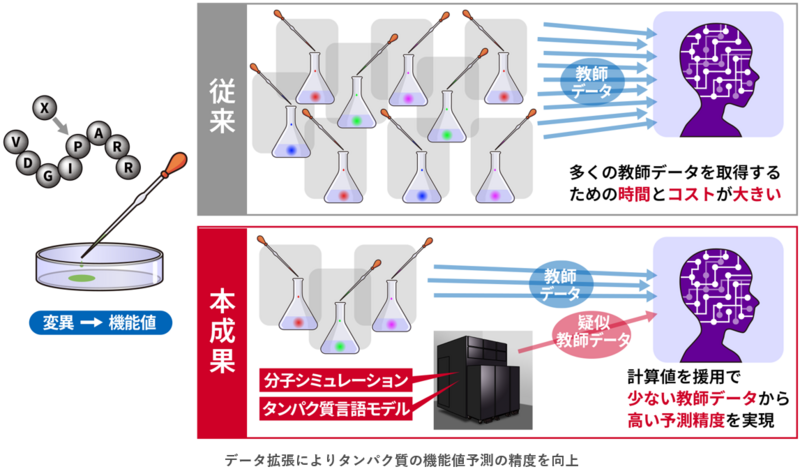
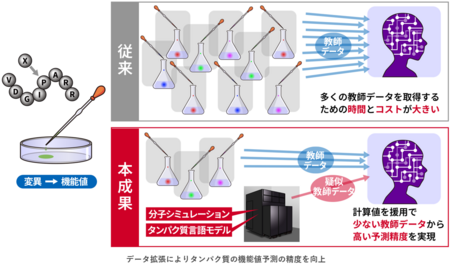
概 要
国立研究開発法人 産業技術総合研究所(以下「産総研」という)人工知能研究センター 出口 鉄平 リサーチアシスタント(東京大学大学院 大学院生)、小林 海渡 研究員、齋藤 裕 特定フェローは、分子シミュレーションとタンパク質言語モデルを用いて、機械学習によりタンパク質の機能値を少数の実験データからでも高精度で予測する手法を開発しました。
近年、機能性タンパク質の設計に向け、機械学習を用いてタンパク質の機能を予測する手法の活用が進んでいます。しかし、教師データとして大量の実験データが必要で、時間的にも物的にも大きなコストがかかります。そこで、実験データに加えて、計算値を疑似的な教師データとして利用する手法が注目されています。これまでは、タンパク質の安定性予測について適用されていましたが、目的に応じた機能性タンパク質を設計するためには、結合親和性や酵素活性の予測などにも適用範囲を広げる必要があります。
今回、分子シミュレーションとタンパク質言語モデルによって計算した機能値を疑似的な教師データとして活用し、タンパク質の機能値を予測する新しい手法を開発しました。その結果、少数の実験データでも精度の高い機能値予測を実現しました。また、タンパク質の安定性以外にも結合親和性、酵素活性、細胞毒性、蛍光強度にも適用範囲を拡大しました。本成果により、既存手法よりも効率的な機能性タンパク質の開発が可能になります。
なお、この研究成果の詳細は、2025年10月10日に「Briefings in Bioinformatics」に掲載されました。
下線部は【用語解説】参照
開発の社会的背景
生体分子の一種であるタンパク質は生体内でさまざまな役割を担い、酵素として化学反応を触媒したり、抗体として特定分子を認識したりします。これらの機能は工業や医療分野でも広く活用されています。タンパク質はアミノ酸が鎖のようにつながってできていて、この並び(配列)を改変することで、活性や安定性などの性質を改良した機能性タンパク質を作ることができます。
目的の機能を持つ機能性タンパク質を効率的に設計するために、近年は機械学習を用いてタンパク質の機能を予測する手法の開発が進められています。具体的には、実験で得られた機能値を教師データとしてモデルを学習させ、与えられたアミノ酸配列に対して機能値を予測します。しかし、高精度に予測するためには教師データとして大量の実験データが必要となるため、時間的にも物的にも大きなコストがかかります。
この問題を克服する手段の一つとして、教師データの拡張が有効です。これは実験で得られるデータに加えて、シミュレーションなどで求めた計算値を疑似的な教師データとして取り入れることで、モデルの学習を補強します。これまで、タンパク質の安定性の予測について適用されてきましたが、目的とする機能を持ったタンパク質を設計するためには、安定性に加えてタンパク質同士の結合親和性や酵素活性、細胞毒性、蛍光強度といった性質に関しても適用する必要があります。
研究の経緯
タンパク質の機能値を計算する方法としては、分子構造や動きを計算機上で再現し、性質や反応を予測する分子シミュレーションが代表的です。一方、近年では、アミノ酸配列を言語のように扱い自然言語処理の手法で事前学習する、タンパク質言語モデルも注目されています。この方法は公開されている膨大なアミノ酸配列データベースを学習に利用して、実験データを用いずにタンパク質の機能値を計算できます。
産総研では、これまで分子シミュレーションを用いてタンパク質の安定性を向上する研究[1]、また、タンパク質言語モデルの事前学習手法の開発や、タンパク質言語モデルを用いた酵素の機能改良を行ってきました[2][3]。今回、分子シミュレーションとタンパク質言語モデルという異なる原理に基づいた手法を組み合わせて、機械学習の教師データを拡張する新たな方法の開発に取り組みました。
なお、本研究開発は、産総研政策予算プロジェクト「フィジカル領域の生成AI基盤モデルに関する研究開発」に基づき実施されました。
研究の内容
タンパク質の機能予測を行うための機械学習では、タンパク質のアミノ酸配列と実験で測定した機能値のペアを教師データとして用いて、配列から機能値を予測します。実験にかかる時間的・物的コストのため、多くの場合、教師データは少数(例.100種類以下の配列)しか取得できません。このため、少ないデータでも正確に予測できる方法の開発が重要な課題となっていました。
本研究では、このような状況での予測精度を高めることを目標としました。分子シミュレーションとタンパク質言語モデルを用いて、数百種類から数千種類の配列に対して疑似的な教師データを作成し、従来の実験による教師データに追加することで、予測精度を向上します。これら2つの方法は、前者が分子の物理法則に基づき構造やエネルギー変化を計算するのに対し、後者は膨大な配列データから学んだAIが変異の影響を推定するという全く異なる原理に基づいており、両者を組み合わせることで、それぞれを単独で用いるよりも、さらに予測精度を向上することができます。また、疑似的な教師データの信頼度を自動的に調整するための重み付けのアルゴリズムや、精度が下がる場合には利用を控える判断アルゴリズムを新たに開発・導入することで、安全に活用できる仕組みを整えました。
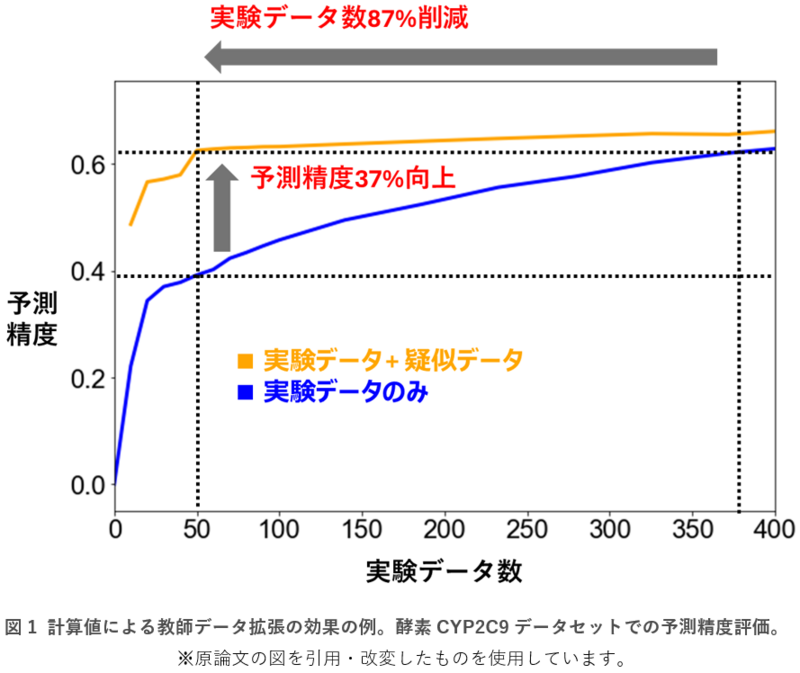
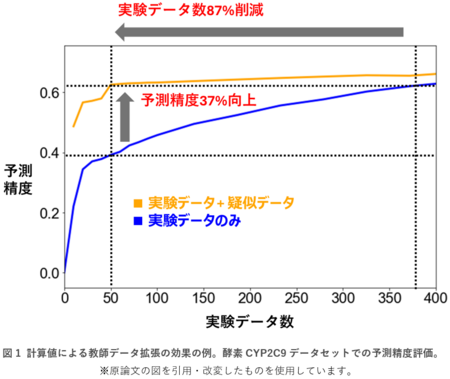
例として、酵素の一種であるCYP2C9の反応活性を予測する問題において、50個の実験データを利用できる状況を想定した評価では、分子シミュレーションとタンパク質言語モデルによる疑似的な教師データを約4,600個追加することで、予測精度を約37%向上することに成功しました(図1)。また、同じ予測精度を達成するための実験データ数を87%削減することにも成功しました(図1)。このような評価を12種類のタンパク質データセットに対して行い、結合親和性、酵素活性、細胞毒性、蛍光強度などさまざまな機能値の予測において本手法の有効性を実証しました。
今後の予定
今後は、本手法を抗体や酵素などの機能性タンパク質の開発に活用し、有効性を実証します。また、本手法を利用した機能性タンパク質設計システムを実用化し、大学・企業などの機能性タンパク質開発の現場への普及を目指します。
論文情報
掲載誌:Briefings in Bioinformatics
タイトル:Data-efficient protein mutational effect prediction with weak supervision by molecular simulation and protein language models
著者名:Teppei Deguchi, Nur Syatila Ab Ghani, Yoichi Kurumida, Shinji Iida, Kaito Kobayashi, Yutaka Saito
DOI:10.1093/bib/bbaf536
用語解説
分子シミュレーション
コンピュータの中で分子の構造や動きを再現し、分子の性質を予測する技術。
タンパク質言語モデル
タンパク質のアミノ酸配列を「言語」のように学習させ、膨大なデータから性質やはたらきを推測できるAI手法。
タンパク質の機能値
「どれくらいそのはたらきが強いか」を表す数値。例えば酵素の反応活性(酵素活性)や抗体の結合親和性など。
機能性タンパク質
酵素や抗体など、人に役立つはたらきを持つタンパク質。医療や産業利用が期待される。
教師データ
AIを学習させるための「お手本」となるデータ。タンパク質研究では「配列」と「機能値」のペアが使われる。
予測精度
AIが出した予測結果が、実験で測定した実際の機能値とどの程度一致しているかを示す指標。数値が高いほど正確。
引用文献
[1] Shin Irumagawa, Kaito Kobayashi, Yutaka Saito, Takeshi Miyata, Mitsuo Umetsu, Tomoshi Kameda, Ryoichi Arai. Rational thermostabilisation of four-helix bundle dimeric de novo proteins. Scientific Reports, 11(1):7526, 2021. doi: 10.1038/s41598-021-86952-2.
[2] Hideki Yamaguchi, Yutaka Saito. Evotuning protocols for Transformer-based variant effect prediction on multi-domain proteins. Briefings in Bioinformatics, 22(6):bbab234, 2021. doi: 10.1093/bib/bbab234.
[3] Takuma Matsushita, Shinji Kishimoto, Kodai Hara, Hiroshi Hashimoto, Hideki Yamaguchi, Yutaka Saito, Kenji Watanabe. Functional enhancement of flavin-containing monooxygenase through machine learning methodology. ACS Catalysis, 14(9):6945-6951, 2024. doi: 10.1021/acscatal.4c00826.
プレスリリースURL
https://www.aist.go.jp/aist_j/press_release/pr2025/pr20251022/pr20251022.html
編集部からのお知らせ



新着情報






あわせて読みたい








自動車リサイクル促進センター
